Design
CONSIDERATIONS
Containerized
Lives in its own container.
Distributed
There will be multiple instances per site for HA. If one of the instances dies, the queue replica from another instance can be used to process the records.
Extensions
The core engine can be extended to achieve features like asynchronous replication.
Backend agnostic
All interactions will go through S3. This way it is not restricted to one backend and we can reuse existing solutions for different backends.
Background Jobs
Backbeat will include a background tasks which runs on a crontab schedule.
Multi-threaded
Using Kafka’s KeyedMessage mechanism, multiple consumers can process entries in parallel achieving high throughput.
DESIGN OVERVIEW
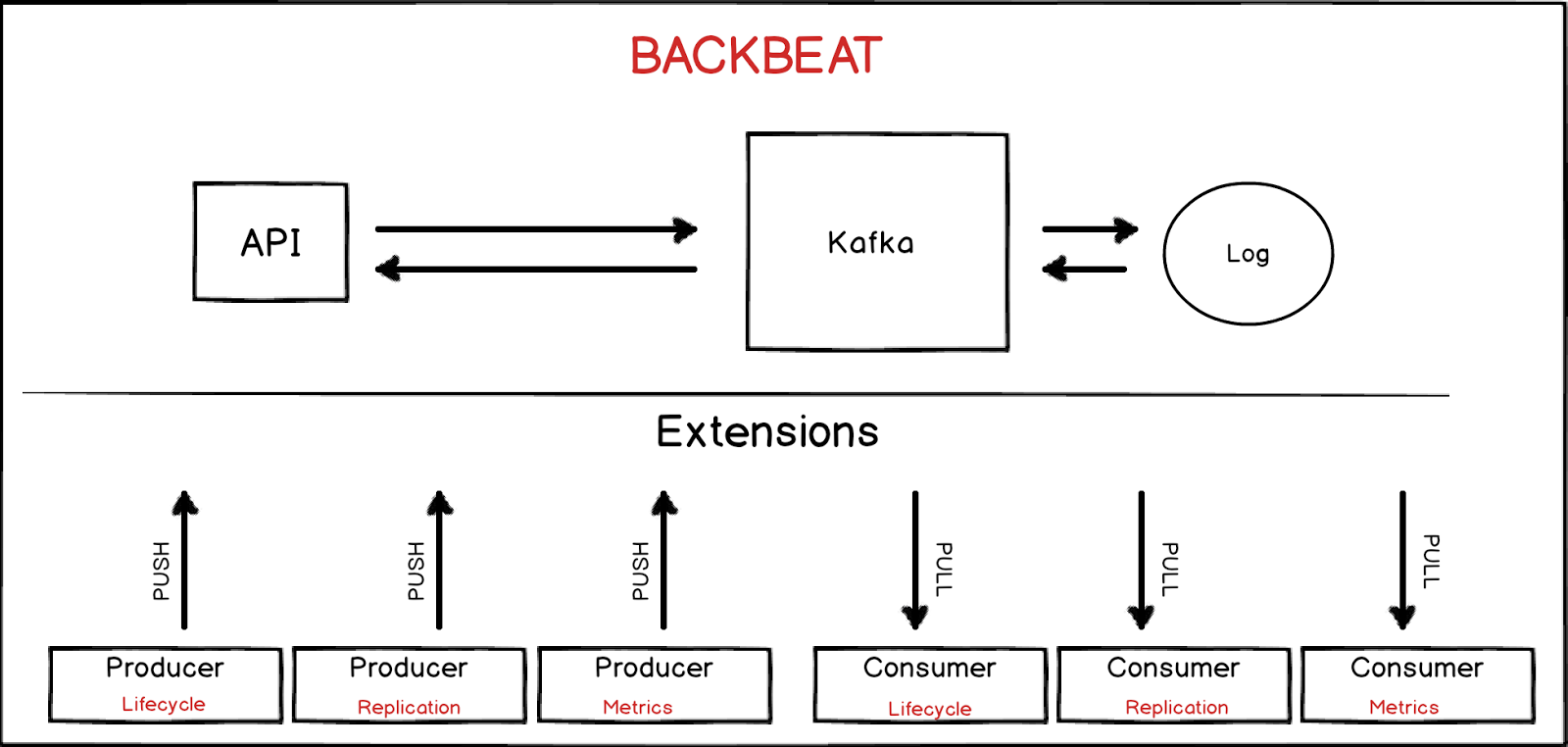
DEPLOYMENT (Mono/Multi-site)
The nodes of a Backbeat cluster must live within one given datacenter. Ideally there will be one standalone cluster per site. Each cluster will have multiple instances for HA.
Backbeat will be the backbone of features like asynchronous replication which rely on such local services to perform remote actions. The basis of replication relies on versioning, Metadata and Data propagation from site to site, which does not need the message queue to be shared between sites (and we don’t want that either because the internals of Backbeat are not necessarily geo-aware.
KAFKA
Kafka is used as a queue manager for Backbeat.
PROS
- Distributed, Pub/Sub, Simple to use, durable replicated log.
- Fast reads and writes using sequential reads/writes to disk.
- Topics contain partitions which are strictly ordered.
- Replication is done on partition level and can be controlled per partition.
- More than one consumer can process a partition achieving parallel processing.
- Can have one consumer processing real time and other consumer processing in batch.
- Easy to add a large number of consumers without affecting performance.
- We can leverage stream processing for encryption, compression etc.
CONS
- Uses Zookeeper but it’s not in the critical path
- Needs optimization for fault tolerance
- Not designed for high latency environments
APPLYING BACKBEAT
USING BACKBEAT FOR ASYNC REPLICATION
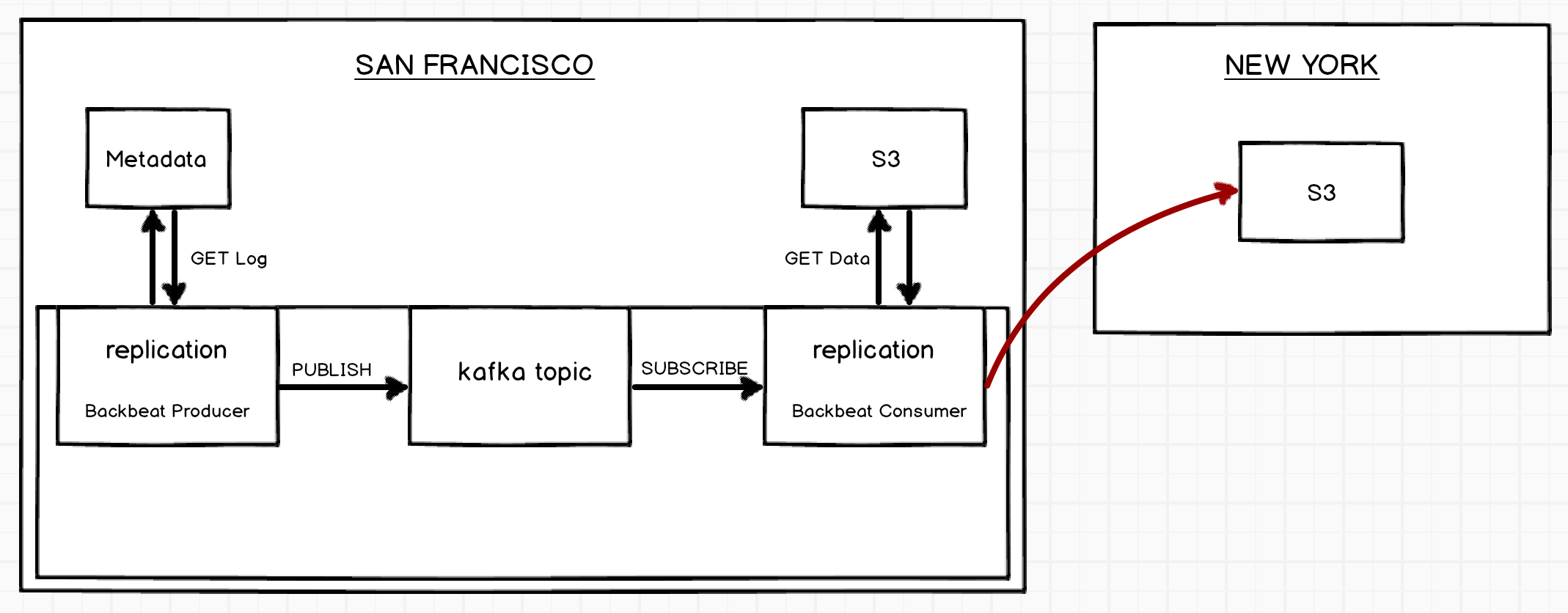
For asynchronous replication, we can use Backbeat to replicate the objects from a bucket of one region to the other. The design highlights how this feature can be achieved by using Backbeat. Reference: AWS rules of what is and what is not replicated http://docs.aws.amazon.com/AmazonS3/latest/dev/crr-what-is-isnot-replicated.html
Note: For Active/Passive setup, the target will be READONLY. This would mean that in a Disaster Recovery setup for a customer, if the customer loses site A they can point themselves to site B to perform READONLY actions until site A comes back up. Although they could write to site B these writes will not be replicated to site A (one of the many reasons being site A may have data that hasn’t been fully replicated to site B when the failure occurred).
-
All replication actions go through S3. S3 exposes routes for Metadata and Data backends to Backbeat.
-
MetaData journal is used as the source of truth.
-
Object metadata will have a new property,
replicationStatus. When a CRR configuration is enabled on a bucket, any S3’s PUT metadata operations on objects matching the configuration will havereplicationStatusasPENDING. -
A producer (background job) wakes up, let’s say every
nseconds, requests journal from Metadata starting from a sequenceId. The producer then queues entries from the journal which havereplicationStatusPENDING into Kafka. -
The entries contain the sequence number as key and a stringified json with fields like action (PUT), object key, object metadata.
-
Backbeat will leverage Kafka’s KeyedMessage mechanism, which guarantees all records with the same key, lets say
<bucket name>:<object key>are written into the same partition and ordering of records is guaranteed within a partition. This gives the advantage of the ability to balance records across all the Kafka nodes and the assignment of multiple consumers to process the queue. -
A consumer picks up from the last committed offset and processes one entry at a time. The consumer first copies data to the target site, updates the object’s metadata with the new location, sets the replicationStatus to
REPLICAand writes the metadata entry at the target. Once the metadata and data operations are completed on the target bucket, the object’s metadata in source bucket is updated to reflect replicationStatus asCOMPLETED. -
If there has been any failure in these sequence of operations for an entry then the object metadata on the source is updated with replicationStatus
FAILED. The consumer will commit the offset of the last successful entry processed to Kafka. On the next run, this entry is tried again.
SECURITY
-
End to End SSL - Use PKI certificates with TLS for trusted communication between the servers. On all the sites(SF, NY, Paris for example), communication occurs through a private route by establishing a TCP connection using the PKI certificates.
-
Temporary credentials - Backbeat will have no credentials (access key, secret key pair) by default and will acquire temporary credentials from IAM to perform actions on users’ resources.
-
A trust policy (IAM actions) will be created allowing the user to assume the role to gain temporary credentials to the source/destination accounts’ resources.
-
Cross account permissions can be managed using ACLs. Access policies (S3 actions) will be created allowing the role to perform specific actions to achieve replication actions. Backbeat first requests temporary credentials from IAM after establishing a trusted communication connection using the certificates. Temporary credentials expire every hour(or some set time). These credentials will be used to communicate with S3 for performing replication actions.
-
Credentials are renewed when they expire. Temporary credentials don’t span across the sites, so Backbeat has to renew credentials on all the sites individually.
-
The setup and behavior will be inline with AWS’ specifications for asynchronous replication. Benefits are that we don’t hardcode any credentials in Backbeat and roles, policies are transparent to the customer who can see what actions we are using for replication. Customers are not expected to maintain or alter these policies, they will be managed by Scality at deploy time.
OSS LICENSES
- Kafka and Zookeeper are the only dependencies of Backbeat which are licensed under Apache License 2.0.
node-rdkafkanpm module which is be used for the producer/consumer actions and maintained by Blizzard Entertainment is licensed under the MIT license.
STATISTICS FOR SLA, METRICS etc
There are two ways we can approach this. Pub/Sub events can be used in addition to the MetaData log in a separate topic (let’s call it statistics). The records in this topic can be leveraged by comparing to the active queue to generate statistics like
- RPO (Recovery Point Objective)
- RTO(Recovery Time Objective)
- Storage backlog in bytes
- Storage replicated so far in bytes
- Number of objects in backlog
- Number of objects replicated so far etc.
Use a decoupled topic in addition to the queue topic. This will be managed by the producers/consumers adding records for non-replicated and replicated entries. Since each entry would have a sequence number, calculating the difference between the sequence numbers of the latest non-replicated and replicated records would give us the required statistics.
WRITING EXTENSIONS
A backbeat extension allows to add more functionality to the core backbeat asynchronous processor. E.g. Asynchronous Replication is one of the extensions available for backbeat.
Extensions are located in the extensions/ directory, with a sub-directory named after the extension name (lowercase).
Extending the Queue Populator
The queue populator is a core backbeat process which reads entries from the metadata log periodically and provides them to all running extensions through the filter() method, while maintaining the offsets of the latest processed log entries.
Extensions can publish messages to one or more kafka topics on reception of particular log entry events.
To achieve this, in the extension module directory, create an ‘index.js’ file exporting the attributes defining the extension metadata and entrypoints, e.g. to create a “mycoolext” extension, put in extensions/mycoolext/index.js:
module.exports = {
name: 'my cool extension',
version: '1.0.0',
queuePopulatorExtension: require('./MyCoolExtensionPopulator.js'),
};
Here, MyCoolExtensionPopulator.js exports a class that:
-
inherits from lib/queuePopulator/QueuePopulatorExtension class
-
implements the filter() method, which gets called whenever new metadata log entries are fetched, with an “entry” argument containing the fields: { bucket, key, type=(put|del), value }
-
calls QueuePopulatorExtension.publish() method from the filter() method to schedule queueing of kafka entries to topics.
Extensions are enabled based on config.json having a sub-section in “extensions” matching the name of the extension directory.
E.g. this config.json enables mycoolext extension, and provides configuration param someparam as “somevalue” to extension classes.
{
[...]
"extensions": {
"mycoolext": {
"someparam": "somevalue"
}
}
}